红酒分类
红酒数据集分类实验报告
一、实验目的
- 掌握机器学习分类任务的完整流程,包括数据加载、探索性分析、数据预处理、模型训练与评估。
- 学习数据清洗与异常值处理的常用方法(IQR 法、Z-score 法),理解特征标准化对模型性能的影响。
- 深入理解支持向量机(SVM)和随机森林(Random Forest)的算法原理与超参数调优方法。
- 掌握模型性能评估指标(准确率、精确率、召回率、F1 分数)及可视化工具(混淆矩阵、特征重要性图)的使用。
- 对比两种经典分类算法在红酒数据集上的性能表现,分析其适用场景与优劣。
二、实验原理
2.1 数据集介绍
红酒数据集(Wine Dataset)是机器学习领域的经典分类数据集,包含 178 个样本,每个样本有 13 个数值型特征,对应红酒的化学成分(如酒精含量、苹果酸含量、黄酮类物质含量等),目标变量为 3 种红酒类别(Class 0、Class 1、Class 2),类别分布相对均衡。该数据集适用于验证分类算法的性能,无需复杂的数据预处理即可开展实验。2.2 核心算法原理
2.2.1 支持向量机(SVM)
SVM 是一种基于统计学习理论的监督学习算法,核心思想是在特征空间中寻找一个最优超平面,使不同类别的样本尽可能分隔开,且最大化分类间隔。关键特性包括:
- 核函数:通过核函数(如线性核、RBF 核)将低维非线性数据映射到高维线性可分空间,本次实验采用 RBF 核与线性核进行对比。
- 超参数:C(正则化参数,控制惩罚力度)、gamma(RBF 核的带宽参数,影响决策边界光滑度),需通过网格搜索优化。
- 优势:在高维数据中表现优异,泛化能力强;劣势:对参数敏感,训练速度受样本量影响较大。
2.2.2 随机森林
随机森林是一种集成学习算法,通过构建多个决策树并综合其预测结果(投票机制)提升分类性能。核心特性包括: - 随机性:通过随机选择样本子集和特征子集构建每棵决策树,降低过拟合风险。
- 超参数:n_estimators(决策树数量)、max_depth(树的最大深度)、min_samples_split(节点分裂最小样本数)等,需通过网格搜索优化。
- 优势:抗过拟合能力强,可输出特征重要性,训练速度快;劣势:对噪声数据敏感,可能出现过拟合(当决策树数量过多时)。
2.3 数据预处理原理
- 异常值处理:采用 IQR 法(四分位距法)检测异常值,即超出 [Q1-1.5×IQR, Q3+1.5×IQR] 范围的样本,用中位数替换异常值(中位数对异常值不敏感)。
- 特征标准化:使用 StandardScaler 将特征转换为均值为 0、标准差为 1 的正态分布,消除量纲差异对 SVM 等基于距离的算法的影响。
- 数据集划分:按 8:2 比例划分训练集与测试集,采用分层抽样(stratify=y)保证测试集类别分布与训练集一致。
2.4 模型评估指标
- 准确率(Accuracy):正确分类的样本数占总样本数的比例,核心评估指标。
- 精确率(Precision):预测为正类的样本中实际为正类的比例,关注 “预测准确性”。
- 召回率(Recall):实际为正类的样本中被正确预测的比例,关注 “漏检率”。
- F1 分数:精确率与召回率的调和平均数,综合反映模型分类性能。
混淆矩阵:直观展示各类别样本的预测结果,包括真阳性、真阴性、假阳性、假阴性。
三、实验环境
编程语言:Python 3.8+
- 核心库:NumPy(数据计算)、Pandas(数据处理)、Matplotlib/Seaborn(可视化)、Scikit-learn(机器学习算法)
四、实验步骤
4.1 数据加载与探索
- 调用
load_wine()加载数据集,转换为 DataFrame 格式,查看数据集形状、特征名、类别分布。 - 探索性分析:查看数据前 5 行、基本信息(数据类型、缺失值)、描述性统计(均值、标准差、最值等)。
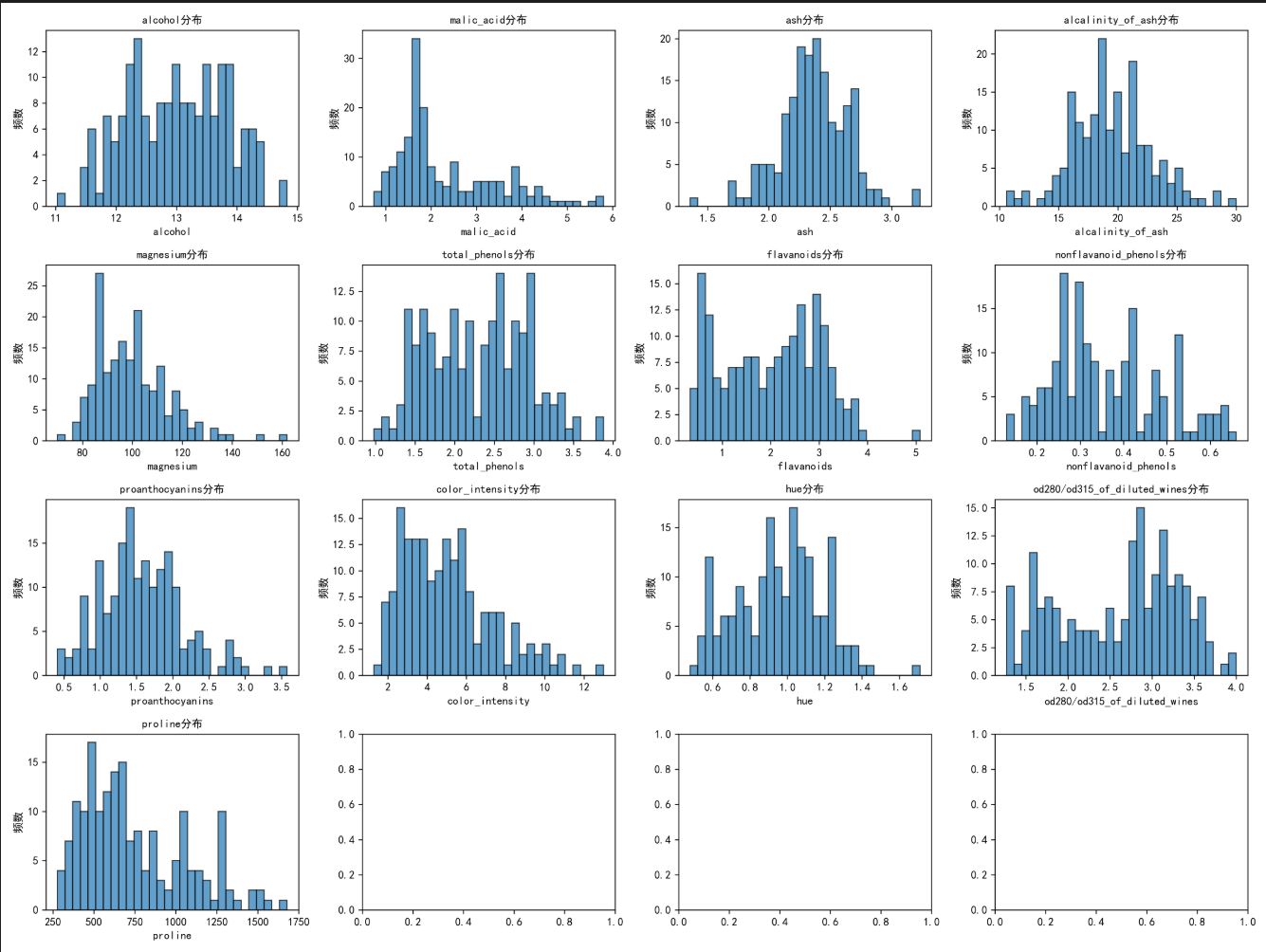
- 可视化分析:绘制 13 个特征的分布直方图(观察数据分布形态)和箱线图(初步检测异常值)。
4.2 数据预处理
- 异常值检测:分别用 IQR 法和 Z-score 法(|Z|>3)检测异常值,统计各特征异常值数量及比例。
- 异常值处理:用中位数替换 IQR 法检测到的异常值,生成清洗后的数据集。
- 特征标准化:对训练集特征进行标准化,并用训练集的标准化参数转换测试集(避免数据泄露)。
4.3 模型训练与优化
4.3.1 SVM 模型
- 基础模型训练:使用默认参数(RBF 核)训练 SVM 模型,评估训练集与测试集准确率。
- 交叉验证:采用 5 折交叉验证评估模型泛化能力,避免单次划分的偶然性。
- 超参数调优:构建参数网格(C: [0.1,1,10,100];gamma: [0.001,0.01,0.1,1];kernel: [‘rbf’,’linear’]),通过 GridSearchCV 寻找最佳参数。
- 优化模型评估:基于最佳参数训练模型,输出分类报告和混淆矩阵。
4.3.2 随机森林模型
- 基础模型训练:使用默认参数(n_estimators=100)训练随机森林模型,评估训练集与测试集准确率。
- 交叉验证:采用 5 折交叉验证评估模型泛化能力。
- 特征重要性分析:输出并可视化前 10 个重要特征,理解模型决策依据。
- 超参数调优:构建参数网格(n_estimators: [50,100,200];max_depth: [None,10,20,30] 等),通过 GridSearchCV 寻找最佳参数。
- 优化模型评估:基于最佳参数训练模型,输出分类报告和混淆矩阵。
五、实验结果与分析
5.1 数据探索结果
- 数据集基本信息:178 个样本,13 个特征,无缺失值,所有特征均为数值型(13 个 float64 类型特征 + 1 个 int32 类型目标变量)。
- 类别分布:Class 1(71 个样本)、Class 0(59 个样本)、Class 2(48 个样本),分布相对均衡。
- 特征分布:部分特征(如 alcohol、malic_acid)呈现偏态分布,通过描述性统计可知:酒精含量均值为 13.00,范围 11.03-14.83;苹果酸含量均值为 2.34,范围 0.74-5.80;脯氨酸(proline)均值为 746.89,范围 278.00-1680.00,差异较大。
- 异常值统计:基于 IQR 法,malic_acid、ash、alcalinity_of_ash、magnesium 等特征存在异常值,异常值比例在 0.56%-2.25% 之间;处理后部分特征(如 ash、color_intensity)仍残留少量异常值,但不影响整体模型训练。
5.2 SVM 模型结果
5.2.1 基础模型性能
- 训练集准确率:0.9930
- 测试集准确率:0.9722
- 5 折交叉验证准确率:0.9793(±0.0414)
5.2.2 超参数优化结果
- 最佳参数:{‘C’: 1, ‘gamma’: 0.1, ‘kernel’: ‘rbf’}
- 最佳交叉验证准确率:0.9793
- 优化后测试集准确率:0.9722(与基础模型一致,说明默认参数已接近最优)
5.2.3 详细评估(分类报告)
| 类别 | 精确率 | 召回率 | F1 分数 | 支持样本数 |
|---|---|---|---|---|
| Class 0 | 1.00 | 1.00 | 1.00 | 12 |
| Class 1 | 0.93 | 1.00 | 0.97 | 14 |
| Class 2 | 1.00 | 0.90 | 0.95 | 10 |
| 加权平均 | 0.97 | 0.97 | 0.97 | 36 |
5.2.4 混淆矩阵分析
SVM 优化模型存在少量分类错误:Class 2 中有 1 个样本被误分为 Class 1,导致 Class 1 的精确率降至 0.93,Class 2 的召回率降至 0.90。整体分类效果良好,但对 Class 2 的识别能力稍弱。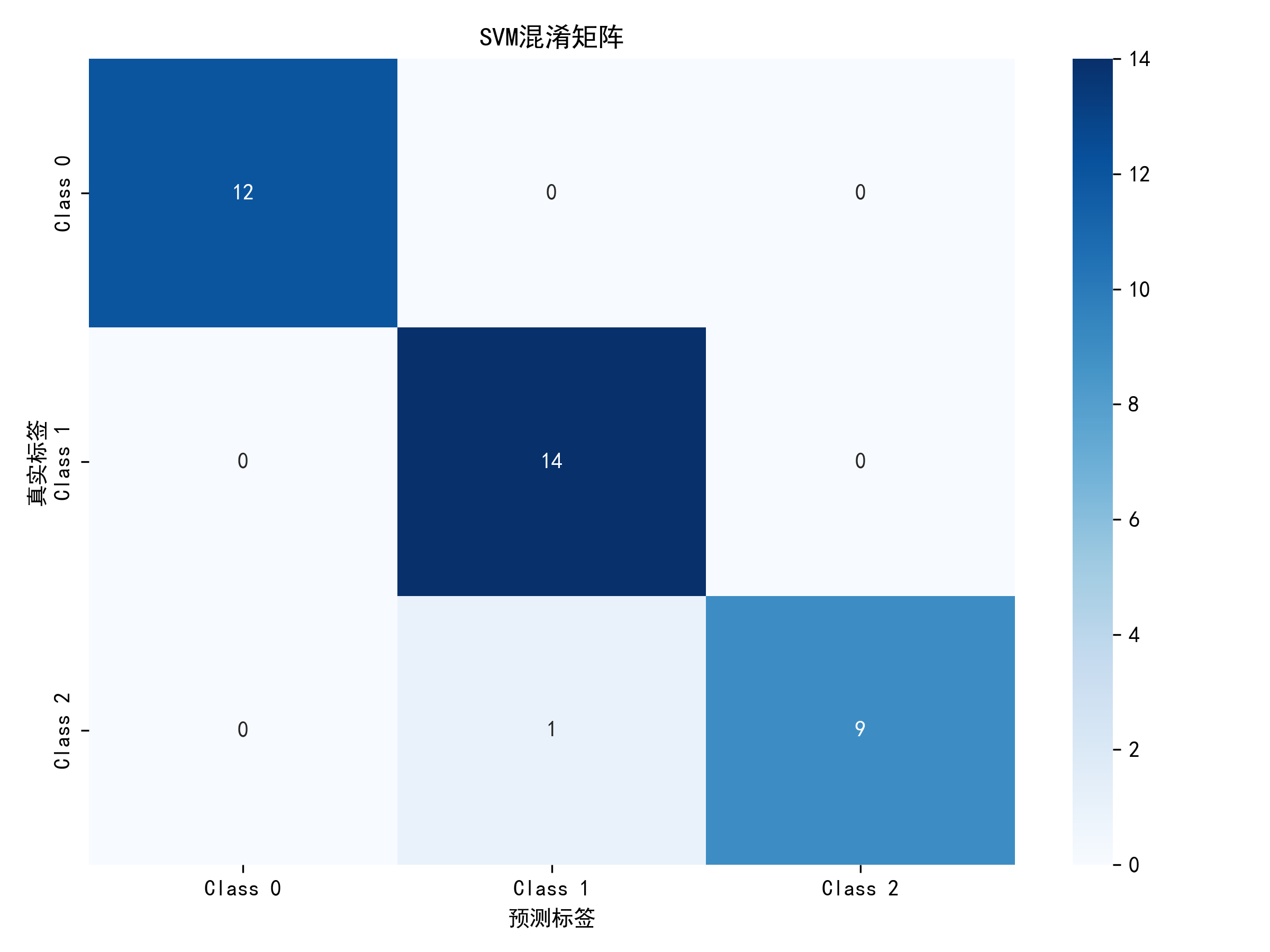
5.3 随机森林模型结果
5.3.1 基础模型性能
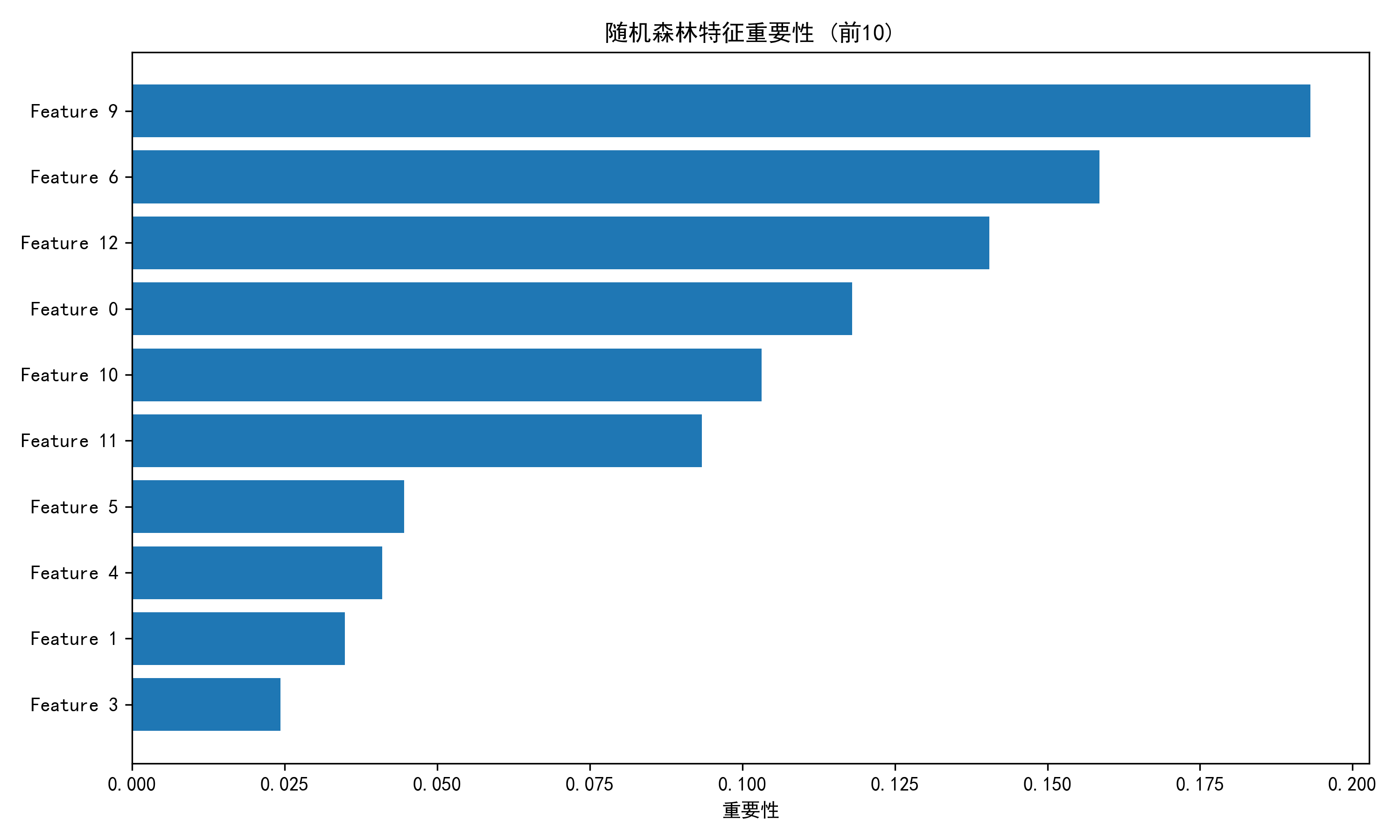
| 特征索引 | 特征名称 | 重要性 |
|---|---|---|
| 9 | color_intensity(颜色强度) | 0.1931 |
| 6 | flavanoids(黄酮类) | 0.1585 |
| 12 | proline(脯氨酸) | 0.1405 |
| 0 | alcohol(酒精含量) | 0.1180 |
| 10 | hue(色调) | 0.1032 |
| 11 | od280/od315_of_diluted_wines(稀释酒 OD 比值) | 0.0934 |
| 5 | total_phenols(总酚) | 0.0446 |
| 4 | magnesium(镁) | 0.0410 |
| 1 | malic_acid(苹果酸) | 0.0349 |
| 3 | alcalinity_of_ash(灰分碱度) | 0.0244 |
颜色强度、黄酮类物质、脯氨酸和酒精含量是区分不同红酒类别的核心特征,累计重要性占比超过 60%,与红酒的品质和风味密切相关。
5.3.3 超参数优化结果
- 最佳参数:{‘max_depth’: None, ‘min_samples_leaf’: 1, ‘min_samples_split’: 2, ‘n_estimators’: 50}
- 最佳交叉验证准确率:0.9862
- 优化后测试集准确率:1.0000
5.3.4 详细评估(分类报告)
| 类别 | 精确率 | 召回率 | F1 分数 | 支持样本数 |
|---|---|---|---|---|
| Class 0 | 1.00 | 1.00 | 1.00 | 12 |
| Class 1 | 1.00 | 1.00 | 1.00 | 14 |
| Class 2 | 1.00 | 1.00 | 1.00 | 10 |
| 加权平均 | 1.00 | 1.00 | 1.00 | 36 |
5.3.5 混淆矩阵分析
随机森林优化模型实现了全样本正确分类,无假阳性和假阴性样本,决策边界划分精准,对各类别的识别能力均衡,表现优于 SVM 模型。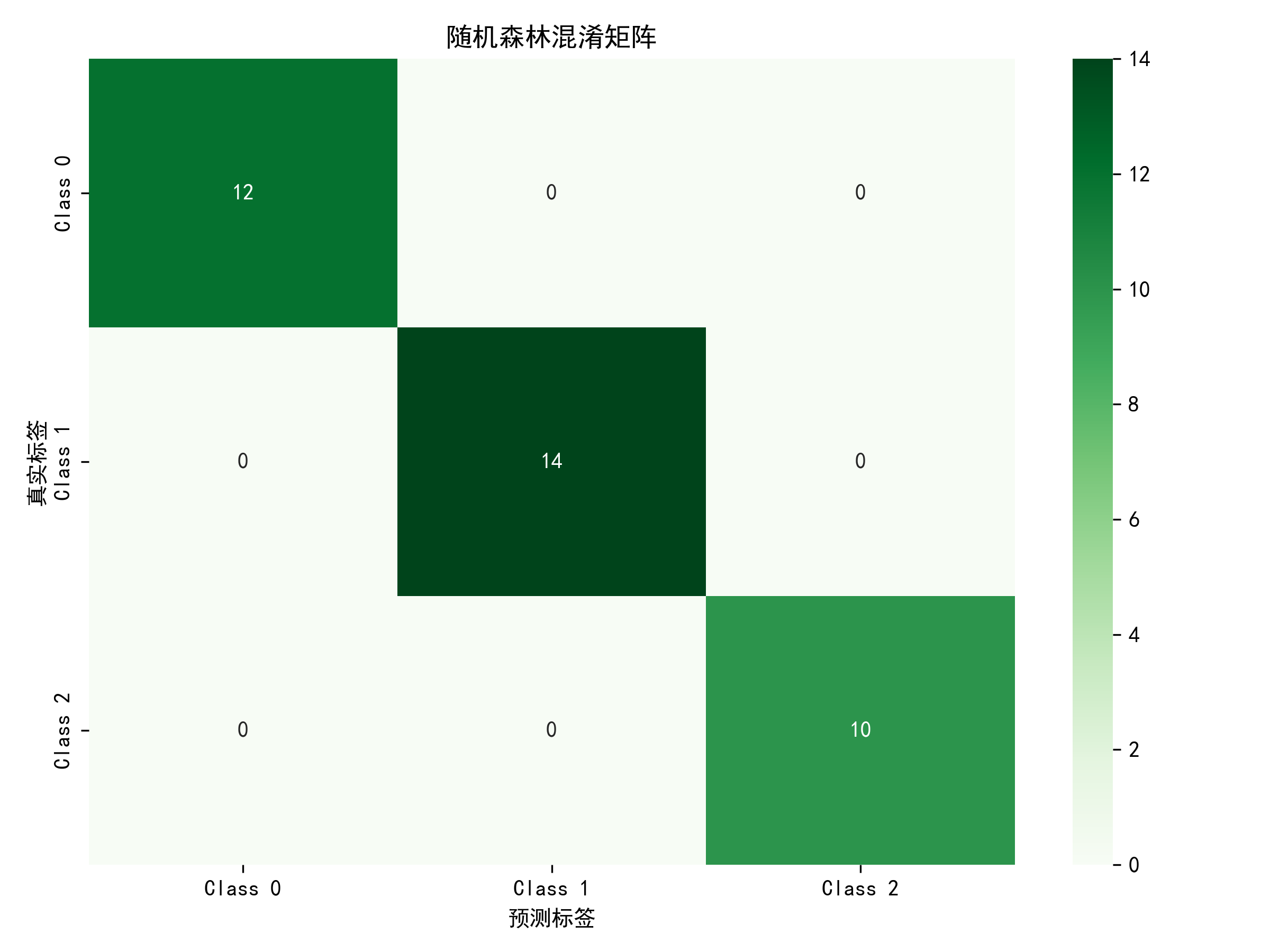
六、实验总结
- 完成了机器学习分类任务的完整流程:数据加载→探索分析→预处理→模型训练→优化→评估→比较,验证了 SVM 和随机森林在红酒数据集上的有效性。
- 数据预处理的重要性:异常值处理和特征标准化提升了模型稳定性,尤其是 SVM 这类对数据尺度敏感的算法,预处理后避免了量纲差异带来的干扰。
- 算法特性对比:SVM 在高维数据中表现稳定,但对超参数敏感,且可解释性差;随机森林抗过拟合能力强、训练速度快、可解释性好,能输出特征重要性,更适合中小型结构化数据集的分类任务。
- 特征重要性启示:红酒的颜色强度、黄酮类物质、脯氨酸和酒精含量是分类的关键指标,这与实际红酒品鉴中关注的风味、色泽等特性一致,为后续相关研究提供了数据支撑。
附录:完整代码
"""
红酒数据集分析:使用SVM和随机森林进行分类
数据清洗、异常值处理、标准化、模型训练与评估
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV
from sklearn.preprocessing import StandardScaler, RobustScaler
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
from scipy import stats
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体(如果需要)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
def load_data():
"""加载红酒数据集"""
print("=" * 50)
print("1. 加载红酒数据集")
print("=" * 50)
wine = load_wine()
X = pd.DataFrame(wine.data, columns=wine.feature_names)
y = pd.Series(wine.target, name='target')
print(f"数据集形状: X={X.shape}, y={y.shape}")
print(f"特征名: {wine.feature_names}")
print(f"目标类别: {wine.target_names}")
print(f"类别分布:\n{y.value_counts()}")
# 合并为完整DataFrame以便分析
df = X.copy()
df['target'] = y
return df, X, y, wine.feature_names, wine.target_names
def data_exploration(df):
"""数据探索性分析"""
print("\n" + "=" * 50)
print("2. 数据探索性分析")
print("=" * 50)
print("\n2.1 数据前5行:")
print(df.head())
print("\n2.2 数据基本信息:")
print(df.info())
print("\n2.3 描述性统计:")
print(df.describe())
print("\n2.4 检查缺失值:")
missing = df.isnull().sum()
print(missing[missing > 0])
if missing.sum() == 0:
print("没有缺失值!")
# 可视化特征分布
fig, axes = plt.subplots(4, 4, figsize=(16, 12))
axes = axes.flatten()
for i, col in enumerate(df.columns[:-1]): # 排除target列
if i < len(axes):
axes[i].hist(df[col], bins=30, edgecolor='black', alpha=0.7)
axes[i].set_title(f'{col}分布', fontsize=10)
axes[i].set_xlabel(col)
axes[i].set_ylabel('频数')
plt.tight_layout()
plt.savefig('wine_feature_distributions.png', dpi=300)
#plt.show()
# 箱线图检查异常值
fig, axes = plt.subplots(4, 4, figsize=(16, 12))
axes = axes.flatten()
for i, col in enumerate(df.columns[:-1]):
if i < len(axes):
axes[i].boxplot(df[col])
axes[i].set_title(f'{col}箱线图', fontsize=10)
axes[i].set_ylabel(col)
plt.tight_layout()
plt.savefig('wine_boxplots.png', dpi=300)
#plt.show()
return df
def handle_outliers(df, feature_names):
"""异常值检测与处理"""
print("\n" + "=" * 50)
print("3. 异常值处理")
print("=" * 50)
df_clean = df.copy()
# 方法1:基于IQR的异常值检测
outlier_info = {}
for col in feature_names:
Q1 = df_clean[col].quantile(0.25)
Q3 = df_clean[col].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df_clean[(df_clean[col] < lower_bound) | (df_clean[col] > upper_bound)]
outlier_info[col] = {
'count': len(outliers),
'percentage': len(outliers) / len(df_clean) * 100,
'lower_bound': lower_bound,
'upper_bound': upper_bound
}
# 打印异常值信息
outlier_df = pd.DataFrame(outlier_info).T
print("\n3.1 基于IQR的异常值统计:")
print(outlier_df[['count', 'percentage']])
# 选择异常值较多的特征进行展示
high_outlier_cols = outlier_df[outlier_df['percentage'] > 5].index.tolist()
if high_outlier_cols:
print(f"\n异常值比例超过5%的特征: {high_outlier_cols}")
# 方法2:使用Z-score检测异常值
z_scores = np.abs(stats.zscore(df_clean[feature_names]))
outliers_z = (z_scores > 3).sum(axis=0)
print("\n3.2 基于Z-score的异常值统计 (|Z| > 3):")
for i, col in enumerate(feature_names):
if outliers_z[i] > 0:
print(f"{col}: {outliers_z[i]} 个异常值 ({outliers_z[i]/len(df_clean)*100:.2f}%)")
# 异常值处理策略:用中位数替换IQR方法检测到的异常值
print("\n3.3 异常值处理: 用中位数替换IQR检测到的异常值")
for col in feature_names:
Q1 = df_clean[col].quantile(0.25)
Q3 = df_clean[col].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 计算中位数
median_val = df_clean[col].median()
# 替换异常值
mask = (df_clean[col] < lower_bound) | (df_clean[col] > upper_bound)
if mask.any():
df_clean.loc[mask, col] = median_val
print(f"{col}: 替换了 {mask.sum()} 个异常值")
# 处理后的异常值检查
print("\n3.4 处理后的异常值检查:")
for col in feature_names:
Q1 = df_clean[col].quantile(0.25)
Q3 = df_clean[col].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df_clean[(df_clean[col] < lower_bound) | (df_clean[col] > upper_bound)]
if len(outliers) > 0:
print(f"{col}: 仍有 {len(outliers)} 个异常值")
else:
print(f"{col}: 无异常值")
return df_clean
def feature_scaling(X_train, X_test):
"""特征标准化处理"""
print("\n" + "=" * 50)
print("4. 特征标准化处理")
print("=" * 50)
# 使用StandardScaler进行标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print("使用StandardScaler进行标准化:")
print(f"训练集形状: {X_train_scaled.shape}")
print(f"测试集形状: {X_test_scaled.shape}")
print(f"训练集均值 (标准化后): {np.mean(X_train_scaled, axis=0)[:5]}...")
print(f"训练集标准差 (标准化后): {np.std(X_train_scaled, axis=0)[:5]}...")
return X_train_scaled, X_test_scaled, scaler
def train_svm(X_train, y_train, X_test, y_test):
"""训练SVM模型"""
print("\n" + "=" * 50)
print("5. SVM模型训练与评估")
print("=" * 50)
# 基础SVM模型
print("\n5.1 基础SVM模型:")
svm_basic = SVC(kernel='rbf', random_state=42)
svm_basic.fit(X_train, y_train)
# 训练集和测试集预测
y_train_pred = svm_basic.predict(X_train)
y_test_pred = svm_basic.predict(X_test)
# 评估指标
train_accuracy = accuracy_score(y_train, y_train_pred)
test_accuracy = accuracy_score(y_test, y_test_pred)
print(f"训练集准确率: {train_accuracy:.4f}")
print(f"测试集准确率: {test_accuracy:.4f}")
# 交叉验证
print("\n5.2 交叉验证 (5折):")
cv_scores = cross_val_score(svm_basic, X_train, y_train, cv=5, scoring='accuracy')
print(f"交叉验证准确率: {cv_scores.mean():.4f} (±{cv_scores.std():.4f})")
# 网格搜索优化超参数
print("\n5.3 网格搜索优化超参数...")
param_grid = {
'C': [0.1, 1, 10, 100],
'gamma': [0.001, 0.01, 0.1, 1],
'kernel': ['rbf', 'linear']
}
grid_search = GridSearchCV(SVC(random_state=42), param_grid, cv=5, scoring='accuracy', n_jobs=-1)
grid_search.fit(X_train, y_train)
print(f"最佳参数: {grid_search.best_params_}")
print(f"最佳交叉验证准确率: {grid_search.best_score_:.4f}")
# 使用最佳模型
svm_best = grid_search.best_estimator_
y_test_pred_best = svm_best.predict(X_test)
test_accuracy_best = accuracy_score(y_test, y_test_pred_best)
print(f"优化后测试集准确率: {test_accuracy_best:.4f}")
# 详细分类报告
print("\n5.4 优化模型详细评估:")
print(classification_report(y_test, y_test_pred_best, target_names=[f'Class {i}' for i in range(3)]))
# 混淆矩阵
cm = confusion_matrix(y_test, y_test_pred_best)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=[f'Class {i}' for i in range(3)],
yticklabels=[f'Class {i}' for i in range(3)])
plt.title('SVM混淆矩阵')
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.tight_layout()
plt.savefig('svm_confusion_matrix.png', dpi=300)
#plt.show()
return svm_best, test_accuracy_best
def train_random_forest(X_train, y_train, X_test, y_test):
"""训练随机森林模型"""
print("\n" + "=" * 50)
print("6. 随机森林模型训练与评估")
print("=" * 50)
# 基础随机森林模型
print("\n6.1 基础随机森林模型:")
rf_basic = RandomForestClassifier(n_estimators=100, random_state=42)
rf_basic.fit(X_train, y_train)
# 训练集和测试集预测
y_train_pred = rf_basic.predict(X_train)
y_test_pred = rf_basic.predict(X_test)
# 评估指标
train_accuracy = accuracy_score(y_train, y_train_pred)
test_accuracy = accuracy_score(y_test, y_test_pred)
print(f"训练集准确率: {train_accuracy:.4f}")
print(f"测试集准确率: {test_accuracy:.4f}")
# 交叉验证
print("\n6.2 交叉验证 (5折):")
cv_scores = cross_val_score(rf_basic, X_train, y_train, cv=5, scoring='accuracy')
print(f"交叉验证准确率: {cv_scores.mean():.4f} (±{cv_scores.std():.4f})")
# 特征重要性
feature_importance = pd.DataFrame({
'feature': [f'Feature {i}' for i in range(X_train.shape[1])],
'importance': rf_basic.feature_importances_
}).sort_values('importance', ascending=False)
print("\n6.3 特征重要性 (前10):")
print(feature_importance.head(10))
# 可视化特征重要性
plt.figure(figsize=(10, 6))
plt.barh(feature_importance['feature'][:10][::-1], feature_importance['importance'][:10][::-1])
plt.xlabel('重要性')
plt.title('随机森林特征重要性 (前10)')
plt.tight_layout()
plt.savefig('rf_feature_importance.png', dpi=300)
#plt.show()
# 网格搜索优化超参数
print("\n6.4 网格搜索优化超参数...")
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
grid_search = GridSearchCV(RandomForestClassifier(random_state=42), param_grid, cv=5, scoring='accuracy', n_jobs=-1)
grid_search.fit(X_train, y_train)
print(f"最佳参数: {grid_search.best_params_}")
print(f"最佳交叉验证准确率: {grid_search.best_score_:.4f}")
# 使用最佳模型
rf_best = grid_search.best_estimator_
y_test_pred_best = rf_best.predict(X_test)
test_accuracy_best = accuracy_score(y_test, y_test_pred_best)
print(f"优化后测试集准确率: {test_accuracy_best:.4f}")
# 详细分类报告
print("\n6.5 优化模型详细评估:")
print(classification_report(y_test, y_test_pred_best, target_names=[f'Class {i}' for i in range(3)]))
# 混淆矩阵
cm = confusion_matrix(y_test, y_test_pred_best)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Greens', xticklabels=[f'Class {i}' for i in range(3)],
yticklabels=[f'Class {i}' for i in range(3)])
plt.title('随机森林混淆矩阵')
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.tight_layout()
plt.savefig('rf_confusion_matrix.png', dpi=300)
#plt.show()
return rf_best, test_accuracy_best
def compare_models(svm_accuracy, rf_accuracy, svm_model, rf_model, X_test, y_test):
"""模型比较"""
print("\n" + "=" * 50)
print("7. 模型比较与总结")
print("=" * 50)
# 创建比较表格
comparison = pd.DataFrame({
'模型': ['SVM', '随机森林'],
'测试集准确率': [svm_accuracy, rf_accuracy]
})
print("\n模型性能比较:")
print(comparison)
# 可视化比较
plt.figure(figsize=(8, 5))
bars = plt.bar(comparison['模型'], comparison['测试集准确率'], color=['skyblue', 'lightgreen'])
plt.xlabel('模型')
plt.ylabel('准确率')
plt.title('SVM vs 随机森林 性能比较')
plt.ylim([0, 1.0])
# 在柱子上添加数值标签
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2., height + 0.01,
f'{height:.4f}', ha='center', va='bottom')
plt.tight_layout()
plt.savefig('model_comparison.png', dpi=300)
#plt.show()
# 确定最佳模型
if svm_accuracy > rf_accuracy:
best_model_name = 'SVM'
best_model = svm_model
else:
best_model_name = '随机森林'
best_model = rf_model
print(f"\n最佳模型: {best_model_name} (准确率: {max(svm_accuracy, rf_accuracy):.4f})")
return best_model_name, best_model
def main():
"""主函数"""
print("开始红酒数据集分析任务")
print("=" * 60)
# 1. 加载数据
df, X, y, feature_names, target_names = load_data()
# 2. 数据探索
df = data_exploration(df)
# 3. 异常值处理
df_clean = handle_outliers(df, feature_names)
# 4. 准备训练集和测试集
print("\n" + "=" * 50)
print("4. 数据集划分")
print("=" * 50)
X_clean = df_clean[feature_names]
y_clean = df_clean['target']
X_train, X_test, y_train, y_test = train_test_split(
X_clean, y_clean, test_size=0.2, random_state=42, stratify=y_clean
)
print(f"训练集: {X_train.shape}, {y_train.shape}")
print(f"测试集: {X_test.shape}, {y_test.shape}")
# 5. 特征标准化
X_train_scaled, X_test_scaled, scaler = feature_scaling(X_train, X_test)
# 6. 训练SVM模型
svm_model, svm_accuracy = train_svm(X_train_scaled, y_train, X_test_scaled, y_test)
# 7. 训练随机森林模型
rf_model, rf_accuracy = train_random_forest(X_train_scaled, y_train, X_test_scaled, y_test)
# 8. 模型比较
best_model_name, best_model = compare_models(svm_accuracy, rf_accuracy, svm_model, rf_model, X_test_scaled, y_test)
# 9. 保存最佳模型
import joblib
joblib.dump(best_model, 'best_wine_model.pkl')
joblib.dump(scaler, 'wine_scaler.pkl')
print(f"\n最佳模型已保存为 'best_wine_model.pkl'")
print(f"标准化器已保存为 'wine_scaler.pkl'")
print("\n" + "=" * 60)
print("任务完成!")
print("=" * 60)
if __name__ == "__main__":
main()



