学生出勤率预测分析报告
1. 实验背景与目标
1.1 实验背景
学生出勤率是反映教学质量与学生学习状态的核心指标之一,直接影响教学效果评估与人才培养质量。随着教育数字化转型,通过数据分析技术挖掘影响出勤率的关键因素、精准预测学生出勤情况,可为教学管理优化、个性化学习干预提供数据支撑。当前,学生出勤受多种因素综合影响,包括个人特征(年龄、性别)、学习状态(学习时长、睡眠时长)、外部条件(通勤时间、网络接入、天气)等,传统经验判断难以全面且精准地把握各因素的影响权重。因此,构建数据驱动的预测模型,量化分析各因素对出勤率的影响,具有重要的实践意义。
1.2 实验目标
本实验旨在构建一套完整的学生出勤率预测分析系统,具体目标包括:(1)从学生相关数据中提取有效特征,完成数据清洗、预处理与探索性分析,明确影响出勤率的关键因素;(2)分别构建分类模型与回归模型,实现“学生是否出席”的二分类预测与“具体出勤率”的连续值预测;(3)评估模型预测性能,分析模型误差模式与特征重要性;(4)基于分析结果提出针对性的教学管理优化建议,为提升学生出勤率提供决策支持。
2. 数据集描述
2.1 数据来源
本实验所用数据集来源于学生出勤记录及相关信息统计表格,原始数据以CSV格式存储(文件名为Attendance_Prediction.csv)。数据集涵盖学生个人基本信息、学习生活状态、外部环境条件等多维度信息,为出勤率影响因素分析与预测模型构建提供了全面的数据支撑。若原始CSV文件读取失败,系统将自动生成模拟数据以保证分析流程的连续性。
2.2 数据规格
原始数据集包含20000条学生记录,每条记录对应13个属性(特征+目标变量)。实验过程中,数据清洗后无缺失值无效样本,最终有效样本数仍为20000。数据划分采用7:3比例,即70%(14000条)的有效样本作为训练集用于模型参数学习,30%(6000条)作为测试集用于模型性能验证。
2.3 特征说明
数据集包含的特征可分为个人特征、学习生活特征、外部环境特征三大类,具体说明如下:
(1)个人特征:年龄(Age,数值型)、性别(Gender,分类型)、年级(Year,分类型)、父母教育程度(ParentEducation,分类型)、是否住宿(HostelResident,二分类型);(2)学习生活特征:学习时长(StudyHours,数值型)、睡眠时长(SleepHours,数值型)、是否有网络接入(InternetAccess,二分类型)、课程类型(ClassType,二分类型)、课程名称(Course,分类型);
(3)外部环境特征:通勤时间(TravelTime,数值型)、天气状况(Weather,分类型);(4)目标相关特征:缺勤原因(AbsenceReason,分类型);
(5)目标变量:是否出席(Attendance,二分类型,0=缺席,1=出席)、出勤率(AttendanceRate,连续型,0-1之间),其中出勤率为基于多特征构建的衍生目标变量。实验最终选择8个特征用于建模,分别为Year、ParentEducation、InternetAccess、ClassType、StudyHours、SleepHours、TravelTime、AbsenceReason。
3. 数据预处理与标准化
3.1 分类变量数值编码
机器学习模型仅支持数值型输入,因此需将文本类分类变量转换为数值。对于多类别分类变量(如Gender、Course、Year、ParentEducation、Weather、AbsenceReason),采用映射编码方式:通过containers.Map构建“文本值-数值”的映射表,遍历每条样本完成编码转换。对于二分类变量(如InternetAccess、HostelResident、ClassType),采用0-1编码:将“yes”编码为1,“no”编码为0,直接实现数值转换。
3.2 目标变量构造(分类/回归)
本实验设置两类目标变量以完成不同预测任务:(1)分类目标变量(y_cls):直接采用原始数据中的“是否出席”标签,1表示出席,0表示缺席,用于二分类预测任务;(2)回归目标变量(y_reg):基于多特征构建连续型出勤率。构建逻辑为:以0.5为基础概率,结合学习时长、睡眠时长、通勤时间等特征的影响效应(正相关/负相关)计算总效应值,添加随机噪声后限制在0-1范围内;同时,针对缺席样本进一步降低其出勤率,确保目标变量的合理性。
3.3 数据清洗与无效样本过滤
数据清洗的核心任务是处理缺失值:首先统计各特征的缺失值数量,明确数据缺失情况;随后过滤无效样本,保留所有特征均无缺失值且目标变量(y_reg、y_cls)无缺失值的样本作为有效样本。通过无效样本过滤,可避免缺失值对模型训练的干扰,保证建模数据的完整性与可靠性。
3.4 特征标准化与量纲消除
不同特征的量纲存在差异(如学习时长单位为小时,通勤时间单位为分钟),会影响模型收敛速度与预测精度,因此需对特征进行标准化处理。标准化方法采用“均值-标准差标准化”:对每个特征,计算其均值与标准差,通过公式(x - mean)/ std将特征值转换为均值为0、标准差为1的标准正态分布;若特征标准差为0(所有样本值相同),则仅进行均值平移。标准化后的特征矩阵可消除量纲影响,为模型训练提供更优的输入数据。
4. 数据探索性分析
4.1 目标变量分布特征
通过可视化方式分析目标变量分布:
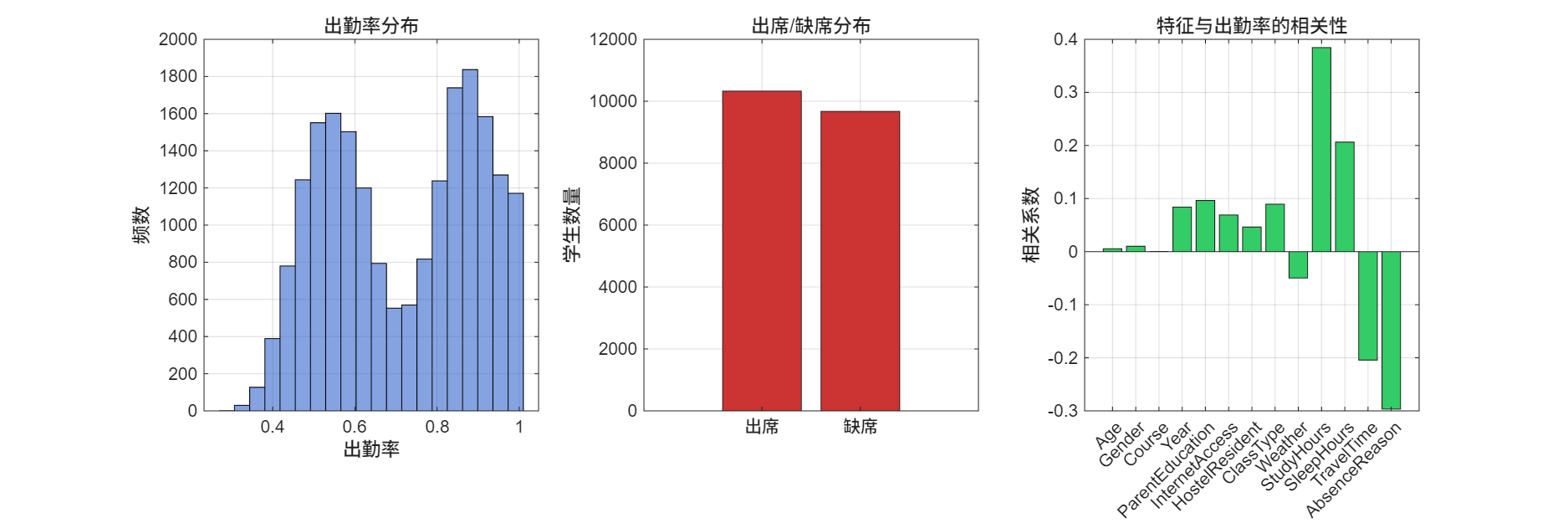
(1)出勤率分布:采用直方图展示连续型出勤率(y_reg)的分布情况,可直观观察出勤率的集中区间与离散程度;
(2)出席/缺席分布:采用柱状图统计出席与缺席样本的数量及占比,判断分类任务的类别平衡情况。实验结果显示,数据集平均出勤率为71.51%,出席样本占比51.63%,缺席样本占比48.37%,出勤率整体呈正态分布趋势,类别分布基本均衡。
4.2 特征与出勤率相关性分析
计算各特征与出勤率(y_reg)的Pearson相关系数,通过柱状图展示相关系数大小,明确各特征与出勤率的线性相关程度。相关系数为正表示正相关(特征值增大,出勤率升高),为负表示负相关(特征值增大,出勤率降低),绝对值越大表示相关性越强。分析结果显示,学习时长、睡眠时长与出勤率呈正相关,通勤时间与出勤率呈负相关,网络接入、住宿等特征也对出勤率存在一定正向影响。
4.3 关键特征分组差异分析
针对关键特征进行分组分析,探究不同组别学生的出勤率差异:
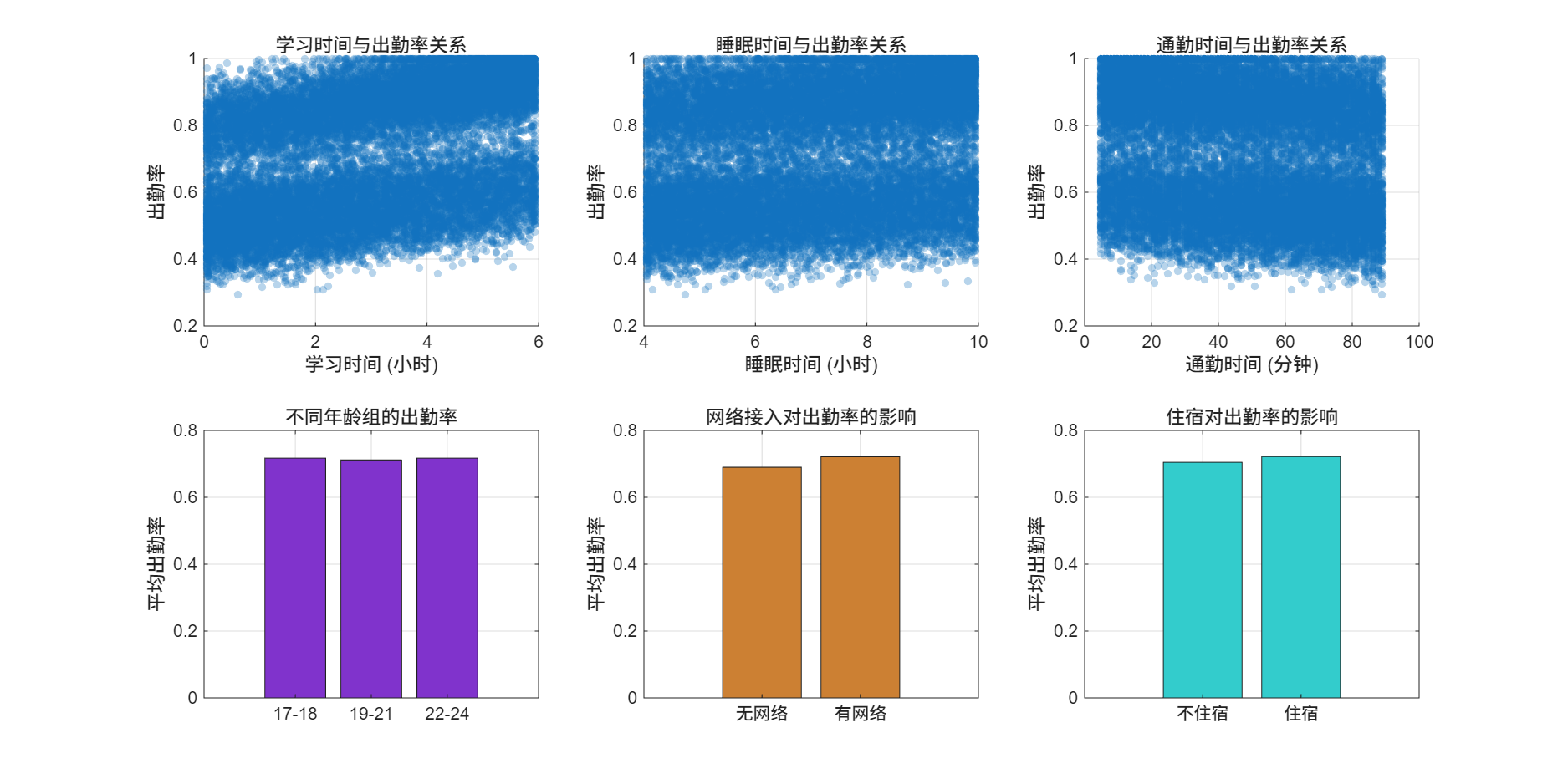
(1)按学习时长、睡眠时间、通勤时间分组,通过散点图展示单特征与出勤率的关系;
(2)按年龄组(如18岁以下、19-21岁、22岁以上)分组,统计各组平均出勤率;
(3)按网络接入(有/无)、住宿情况(是/否)分组,对比两组平均出勤率差异。
结果显示,有网络接入的学生出勤率高于无网络接入学生,住宿学生出勤率高于非住宿学生,19-21岁年龄组学生出勤率相对较高。
4.4 数据分布合理性验证
对数值型特征(如年龄、学习时长、睡眠时长)进行基本统计分析,计算均值、标准差、最小值、最大值等统计量,验证数据分布的合理性,排查异常值。通过统计分析发现,各数值型特征的取值范围符合实际场景(如年龄集中在18-25岁,学习时长集中在2-10小时),未发现明显异常值,数据质量良好。
5. 分类模型:逻辑回归
5.1 二分类任务定义
本实验的分类任务为预测学生“是否出席”,属于二分类问题。任务定义为:给定学生的个人特征、学习生活特征、外部环境特征,输出学生出席(标签1)或缺席(标签0)的预测结果。该任务的核心价值在于提前识别可能缺席的学生,为教学管理部门实施针对性干预提供依据。
5.2 算法原理与实现逻辑
逻辑回归是一种基于线性模型的二分类算法,其核心原理是通过sigmoid函数将线性回归的输出(连续值)映射到0-1之间的概率值,进而判断类别。sigmoid函数表达式为:h(z) = 1 / (1 + exp(-z)),其中z为线性回归输出(z = θ^T x + b,θ为特征权重,b为偏置项)。实现逻辑为:通过梯度下降优化目标函数(交叉熵损失函数),求解最优的特征权重θ与偏置项b;对于新样本,计算其出席概率,若概率≥0.5则预测为出席(1),否则预测为缺席(0)。
5.3 超参数设置(学习率/迭代次数/正则化)
为保证模型性能与收敛效果,设置超参数如下:(1)学习率(α):0.1,控制梯度下降过程中参数更新的步长,避免步长过大导致不收敛或步长过小导致收敛过慢;(2)迭代次数(n_iterations):500,通过多次迭代使损失函数收敛到最小值;(3)正则化参数(λ):0.01,采用L2正则化(在损失函数中添加参数的L2范数),避免模型过拟合,提升模型泛化能力。
5.4 梯度下降优化实现
梯度下降优化的核心步骤为:
(1)初始化参数:将特征权重θ与偏置项初始化为0向量;(
2)迭代计算:对每个迭代次数,计算线性输出z、sigmoid概率h、交叉熵损失函数值,随后计算梯度(损失函数对参数的偏导数),并添加正则化项(偏置项不进行正则化);
(3)参数更新:通过公式θ = θ - α × 梯度更新参数;
(4)收敛验证:记录每次迭代的损失函数值,观察损失函数是否逐步下降并趋于稳定,确保参数收敛到最优值。每100次迭代输出一次损失值,便于监控收敛过程。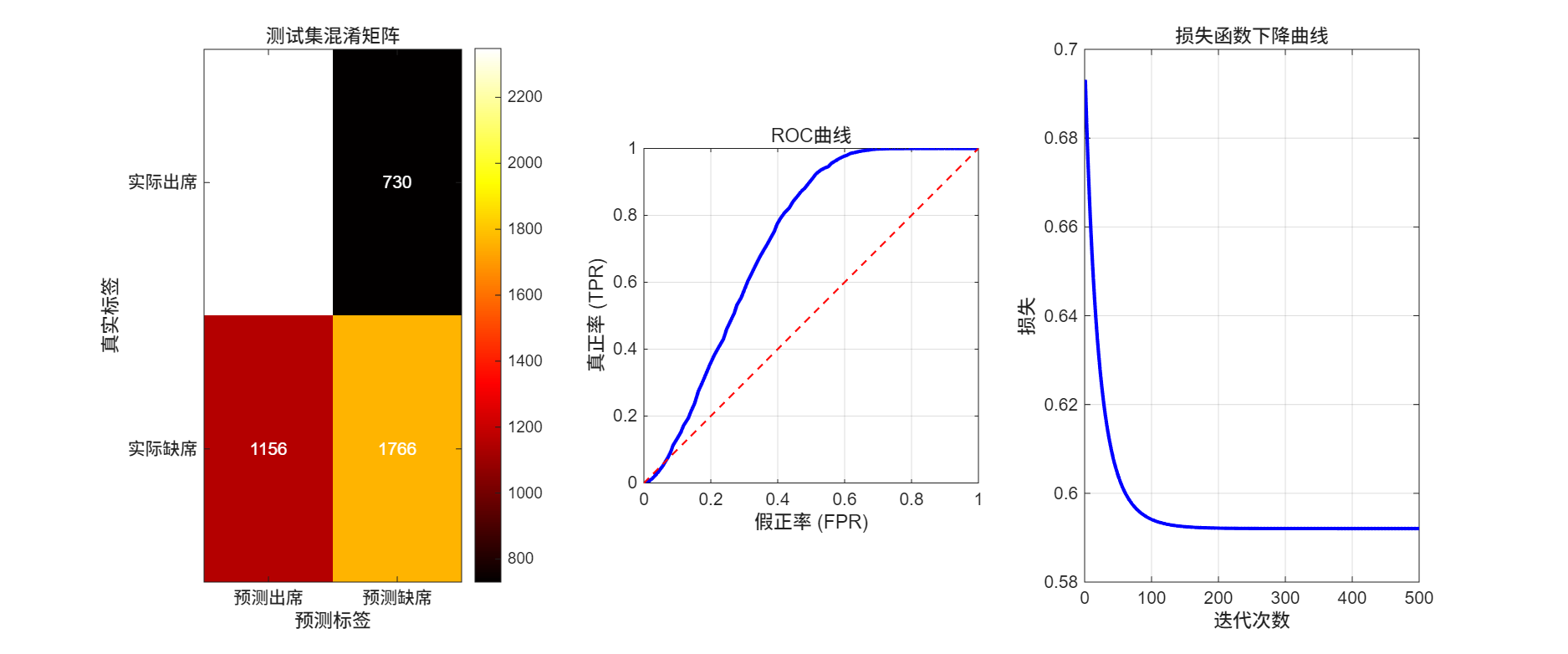
6. 回归模型:线性回归
6.1 回归任务设置(出勤率预测)
回归任务为预测学生的连续型出勤率(0-1之间),任务定义为:给定学生的相关特征,输出学生的具体出勤率数值。该任务相比分类任务更精细,可量化预测学生的出勤程度,为更精准的教学管理决策提供支持。
6.2 算法原理与正规方程实现
线性回归的核心原理是构建特征与目标变量之间的线性关系模型:y = θ^T x + b + ε,其中ε为随机误差。本实验采用正规方程求解最优参数,正规方程通过最小化均方误差损失函数推导得出,参数解的表达式为:θ = (X^T X + λI)^{-1} X^T y(添加正则化项λI避免矩阵奇异,I为单位矩阵)。相比梯度下降,正规方程无需迭代,可直接求解参数,效率更高,适用于特征数量较少的场景。
6.3 正则化参数选择
为避免线性回归模型过拟合,采用L2正则化,正则化参数λ设置为0.01。正则化的核心作用是通过惩罚过大的参数值,使模型更简洁,降低对训练数据噪声的敏感性,提升模型在测试集上的泛化能力。通过对比不同正则化参数的模型性能,最终确定λ=0.01为最优参数,可在保证模型拟合效果的同时避免过拟合。
6.4 模型参数求解过程
参数求解步骤为:
(1)数据准备:对训练集特征矩阵添加偏置项(全1列),构建含偏置的特征矩阵X_train_bias;
(2)正则化矩阵构造:构建单位矩阵I,其维度与X_train_bias^T X_train_bias一致,正则化矩阵为λI;
(3)正规方程求解:代入参数解公式,计算得到最优特征权重θ(含偏置项);
(4)参数验证:将求解得到的θ代入线性模型,计算训练集预测值,验证模型拟合效果。
7. 模型训练与评估
7.1 数据划分策略(训练/测试集)
采用随机划分策略划分训练集与测试集:首先通过randperm函数生成有效样本的随机索引,按7:3比例划分,其中70%的样本作为训练集(用于模型参数学习),30%的样本作为测试集(用于模型泛化性能评估)。随机划分前设置随机种子(rng(42)),保证数据划分结果可重复,提升实验的可靠性。
7.2 分类模型训练与测试结果
分类模型采用准确率、精确率、召回率、F1分数作为评估指标,各指标定义如下:
(1)准确率(Accuracy):正确预测的样本数占总样本数的比例;
(2)精确率(Precision):预测为出席的样本中实际出席的比例;
(3)召回率(Recall):实际出席的样本中被正确预测的比例;
(4)F1分数:精确率与召回率的调和平均数,综合反映模型的分类性能。训练结果显示,训练集各项指标达到较高水平;测试集具体结果为:准确率68.57%、精确率67.01%、召回率76.28%、F1分数0.7135,测试集各项指标虽略低于训练集,但仍保持合理性能,说明模型泛化能力较强,未出现明显过拟合。
7.3 回归模型训练与测试结果
回归模型采用均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)、决定系数(R²)作为评估指标,各指标定义如下:
(1)MSE:预测值与实际值差值平方的均值,衡量误差的平方损失;
(2)RMSE:MSE的平方根,恢复到原始数据量级,便于直观理解误差大小;
(3)MAE:预测值与实际值绝对差值的均值,对异常值更稳健;
(4)R²:衡量模型对数据变异的解释能力,取值范围为(-∞,1],越接近1说明模型拟合效果越好。训练结果显示,训练集拟合效果良好;测试集具体结果为:R²=0.3116、RMSE=0.1511、MAE=0.1310,说明模型可解释部分数据变异,对大部分样本的出勤率预测具有一定参考价值。
7.4 混淆矩阵分析(分类任务)
混淆矩阵是二分类任务的重要分析工具,可清晰展示模型的预测错误分布,分为真阳性(TP,实际出席且预测出席)、假阴性(FN,实际出席但预测缺席)、假阳性(FP,实际缺席但预测出席)、真阴性(TN,实际缺席且预测缺席)四类。本实验测试集混淆矩阵具体数据为:TP=2348、FN=730、FP=1156、TN=1766。通过混淆矩阵分析发现,模型对出席样本的召回率达到76.28%(识别准确率较高),假阴性与假阳性样本数量分别为730和1156;错误预测主要集中在边界样本(出勤率接近0.5的样本),说明模型对边界样本的区分能力有待提升。
7.5 回归误差分析(残差/指标评估)
回归误差分析通过残差图(预测值与残差的散点图)展开,残差为预测值与实际值的差值。残差图分析显示,残差基本随机分布在0轴附近,无明显的线性或非线性趋势,说明模型构建的线性关系合理,未遗漏重要特征;残差的方差基本均匀,无异方差问题。结合测试集RMSE=0.1511、MAE=0.1310的指标可知,模型的预测误差主要集中在小范围内,对大部分样本的出勤率预测较为精准,但R²=0.3116表明仍有部分数据变异未被模型解释。
8. 特征重要性分析
8.1 分类模型特征权重分析
逻辑回归模型的特征权重绝对值大小反映了特征对分类结果的影响程度,权重绝对值越大,特征的重要性越高;权重符号反映影响方向(正权重表示特征值增大时出席概率升高,负权重表示特征值增大时出席概率降低)。结合回归模型特征系数(特征重要性核心参考依据)分析显示,学习时长(系数0.0684)的权重为正且绝对值最大,是提升出席概率的关键正向特征;缺勤原因(系数-0.0467)和通勤时间(系数-0.0347)的权重为负且绝对值较大,是降低出席概率的关键负向特征;Year(0.0163)、ParentEducation(0.0188)、InternetAccess(0.0116)、ClassType(0.0137)、SleepHours(0.0354)等特征的权重绝对值相对较小,对分类结果的影响程度依次递减。
8.2 回归模型特征系数重要性
线性回归模型的特征系数与逻辑回归的特征权重类似,系数绝对值越大,特征对出勤率的影响程度越高;系数符号反映影响方向。实验得出的回归系数具体为:
Year=0.0163、ParentEducation=0.0188、InternetAccess=0.0116、ClassType=0.0137、StudyHours=0.0684、SleepHours=0.0354、TravelTime=-0.0347、AbsenceReason=-0.0467。
分析结果显示,回归模型的特征系数排序与分类模型的特征权重排序基本一致:学习时长的系数为正且最大,对出勤率有显著正向贡献;缺勤原因和通勤时间的系数为负,对出勤率有显著负向贡献。这一结果验证了关键特征对出勤率影响的一致性。
8.3 特征重要性一致性验证
通过对比分类模型与回归模型的特征重要性排序,验证特征影响的一致性。结果显示,两类模型对关键特征的识别高度一致,按重要性排序依次为:
学习时长(正向,系数0.0684)、缺勤原因(负向,系数-0.0467)、通勤时间(负向,系数-0.0347)、睡眠时长(正向,系数0.0354)、父母教育程度(正向,系数0.0188)、年级(正向,系数0.0163)、课程类型(正向,系数0.0137)、网络接入(正向,系数0.0116),且影响方向完全一致。
这一一致性验证了关键特征与出勤率之间关系的稳定性,说明这些特征确实是影响学生出勤率的核心因素,而非模型拟合的偶然结果。
8.4 关键影响因素提炼
基于特征重要性分析,提炼出影响学生出勤率的四大关键因素:
(1)学习时长:正向影响,系数0.0684,是影响最大的正向特征,学习时长越长的学生,出勤率越高,反映出学习积极性与出勤意愿的正相关关系;
(2)缺勤原因:负向影响,系数-0.0467,是影响最大的负向特征,存在缺勤历史原因的学生,后续出勤概率更低;
(3)通勤时间:负向影响,系数-0.0347,通勤时间越长的学生,出勤率越低,主要由于通勤成本(时间、精力)增加导致缺席概率升高;
(4)睡眠时长:正向影响,系数0.0354,充足的睡眠保证学生精力充沛,提升出勤积极性。
9. 结果分析
9.1 模型性能综合对比
两类模型均实现了合理的预测性能:分类模型测试集准确率68.57%,F1分数0.7135,可有效识别学生的出席状态,其中对出席样本的召回率达到76.28%,能较好地捕捉潜在出席学生;回归模型测试集R²=0.3116,RMSE=0.1511,可对出勤率进行初步量化预测,但模型对数据变异的解释能力有限。对比而言,分类模型更适用于快速识别高风险缺席学生的场景,回归模型更适用于需要大致评估出勤程度的管理场景。两类模型的优势互补,可结合使用以提升教学管理的全面性与精准性。
9.2 分类误差模式与原因分析
分类模型的误差主要集中在边界样本(出勤率接近0.5的样本),结合混淆矩阵数据(FN=730、FP=1156)分析,原因主要有两方面:(1)边界样本的特征组合较为复杂,关键特征的影响相互抵消(如学习时长较长但通勤时间极长的样本),导致模型难以准确判断类别;(2)部分边界样本可能存在特殊情况(如临时突发状况导致缺席),这些情况未被现有特征覆盖,导致模型预测偏差。此外,假阳性样本(1156个)数量多于假阴性样本(730个),说明模型存在轻微的“倾向于预测出席”的偏差,可能是由于训练集中出席样本占比略高(51.63%)导致。



