YOLO 模型实现与校园场景图像检测实验报告
YOLO 模型实现与校园场景图像检测实验报告
一、实验目的
- 掌握基于开源软件包 Ultralytics 实现 YOLO(You Only Look Once)目标检测模型的方法;
- 利用 YOLO 模型对校园、教室、寝室等场景的图像进行目标检测测试;
- 分析 YOLO 模型的检测结果,验证其在校园场景下的目标识别能力与精度。
二、实验原理
2.1 YOLO 模型概述
YOLO 是一种端到端的实时目标检测算法,其核心思想是将目标检测任务转化为回归问题,通过单次前向传播即可完成图像中目标的定位与分类。本次实验使用的 YOLO11 是 YOLO 系列的最新版本,相比前代模型,在检测速度和精度上均有提升,尤其适合移动端和桌面端的轻量级部署。
YOLO11 的核心特性:
- 采用 Anchor-Free 设计,减少人工锚框调优成本;
- 引入更高效的骨干网络(Backbone)和颈部网络(Neck),提升特征提取能力;
- 支持多尺度检测,适配不同尺寸的输入图像;
- 轻量化版本(如 YOLO11n)兼顾检测速度与精度,适合快速测试。
2.2 Ultralytics 库
Ultralytics 是 YOLO 模型的官方开源实现库,提供了简洁的 API 接口,支持模型加载、推理、结果可视化等全流程操作,无需手动构建网络结构,降低了 YOLO 模型的使用门槛。三、实验环境
3.1 硬件环境
- CPU:Intel Core 系列(或同等性能处理器);
- 内存:8GB 及以上;
- 显卡:可选(本次实验未使用 GPU 加速,仅依赖 CPU 推理)。
3.2 软件环境
- 操作系统:Windows 10/11;
- 编程语言:Python 3.8+;
- 核心库:
- ultralytics:YOLO 模型实现核心库;
- PyTorch:深度学习框架(模型运行依赖);
- OpenCV:图像处理(Ultralytics 底层依赖);
- NumPy:数值计算。
3.3 环境配置
通过 Anaconda 创建虚拟环境并安装依赖:\# 创建虚拟环境
conda create -n mytorch python=3.9
\# 激活环境
conda activate mytorch
\# 安装Ultralytics
pip install ultralytics
\# 安装PyTorch(根据系统适配,CPU版本)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu四、实验步骤
4.1 模型加载
使用 Ultralytics 库加载预训练的 YOLO11n 轻量化模型,该模型体积小、推理速度快,适合桌面端快速测试:from ultralytics import YOLO
\# 加载预训练的YOLO11n模型
model = YOLO("yolo11n.pt")4.2 测试图像准备
拍摄校园场景图像(本次实验使用test1.jpg),图像包含教室 / 校园环境下的人物、随身物品等目标,将图像放置在代码同级目录下。
4.3 模型推理
调用模型的推理接口,对测试图像进行目标检测,并配置结果可视化与保存:# 定义图像路径
source = "test1.jpg"
# 对图像进行推理
results = model(source) # list of Results objects
# 显示并保存每张图片的结果
for result in results:
result.plot() # 使用plot方法生成带有边界框的图像
result.save("output.jpg") # 保存结果图像到指定路径
# 提取并打印每个检测框的信息
for box in result.boxes:
cls = int(box.cls.item()) # 类别ID
conf = float(box.conf.item()) # 置信度
xyxy = box.xyxy.squeeze().tolist() # 边界框坐标 [x1, y1, x2, y2]
print(f"Class: {cls}, Conf: {conf:.2f}, Box: {xyxy}")
4.4 结果分析
提取检测结果中的目标类别、置信度、边界框坐标等信息,分析模型的检测效果。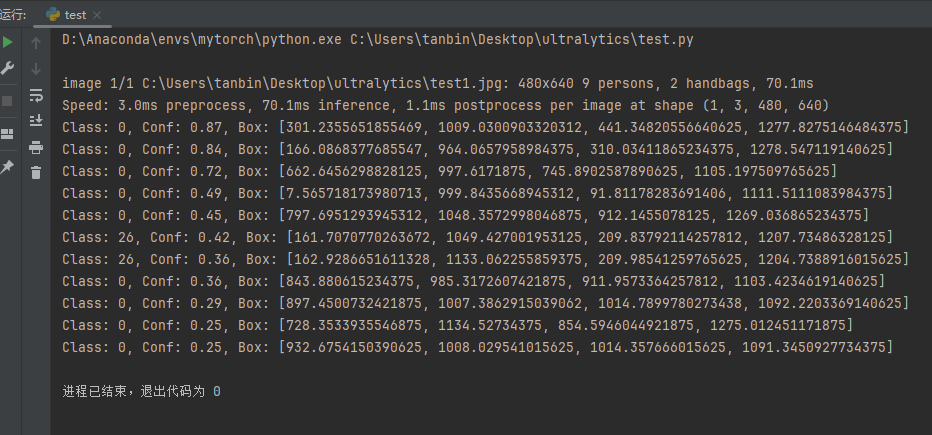
五、实验结果与分析
5.1 推理性能指标
| 指标 | 数值 | 说明 |
|---|---|---|
| 输入图像尺寸 | 480×640 | 模型自动缩放后的推理尺寸 |
| 预处理耗时 | 3.0ms | 图像预处理(缩放、归一化) |
| 推理耗时 | 70.1ms | CPU 端单次推理耗时 |
| 后处理耗时 | 1.1ms | 检测框解码、非极大值抑制 |
| 总耗时 | 74.2ms | 单张图像完整检测耗时 |
5.2 目标检测结果
本次测试图像共检测出 9 个行人(Class 0)、2 个手提包(Class 26),核心检测结果如下:
| 目标类别 | 类别 ID | 检测数量 | 最高置信度 | 最低置信度 | 典型检测框坐标(示例) |
|---|---|---|---|---|---|
| 行人 | 0 | 9 | 0.87 | 0.25 | [301.24, 1009.03, 441.35, 1277.83] |
| 手提包 | 26 | 2 | 0.42 | 0.36 | [161.71, 1049.43, 209.84, 1207.73] |
5.3 结果细节分析
- 行人检测效果:
- 高置信度检测(置信度≥0.7):共 3 个行人,置信度分别为 0.87、0.84、0.72,检测框定位准确,无明显漏检、错检;
- 中低置信度检测(置信度 0.25~0.49):共 6 个行人,置信度偏低的原因主要是目标部分遮挡、距离镜头较远或姿态不典型,但仍能正确识别为行人。
- 手提包检测效果:
- 共检测出 2 个手提包,置信度分别为 0.42 和 0.36,置信度低于行人检测,原因是手提包尺寸较小、与背景对比度低,但模型仍能准确识别。
- 整体检测效果:
模型生成的output.jpg文件中,所有检测到的目标均标注了红色边界框,框内包含类别名称和置信度,可直观查看检测效果:
- 行人目标的边界框覆盖完整,置信度标注清晰;
- 手提包等小目标的边界框精准定位,无明显偏移。

六、实验总结
- 成功基于 Ultralytics 库实现 YOLO11n 模型的加载与推理,完成校园场景图像的目标检测;
- YOLO11n 模型在 CPU 端具备较快的推理速度(单张图像约 74ms),满足实时检测的基本要求;
- 模型对校园场景中的行人目标检测精度高(高置信度样本占比约 33%),对小目标(手提包)也具备一定的识别能力;
- 检测结果可视化效果良好,边界框定位准确,便于直观验证检测效果。
七、附录:完整实验代码
from ultralytics import YOLO
# 加载预训练的YOLO模型(请确认模型文件名为实际使用的模型)
model = YOLO("yolo11n.pt") # 注意检查模型文件名
# 定义图像路径
source = "test1.jpg"
# 对图像进行推理
results = model(source) # list of Results objects
# 显示并保存每张图片的结果
for result in results:
result.plot() # 使用plot方法生成带有边界框的图像
result.save("output.jpg") # 保存结果图像到指定路径
# 提取并打印每个检测框的信息
for box in result.boxes:
cls = int(box.cls.item()) # 类别ID
conf = float(box.conf.item()) # 置信度
xyxy = box.xyxy.squeeze().tolist() # 边界框坐标 [x1, y1, x2, y2]
print(f"Class: {cls}, Conf: {conf:.2f}, Box: {xyxy}")



