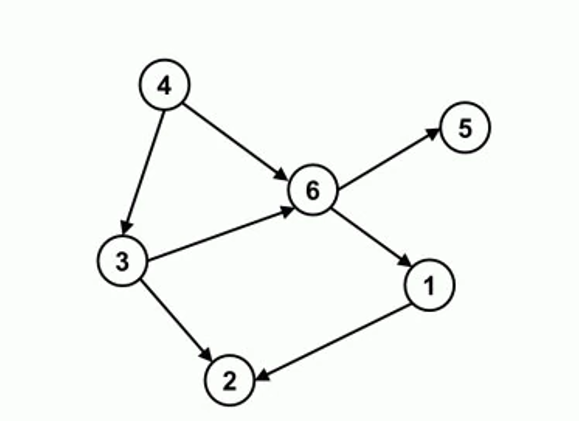
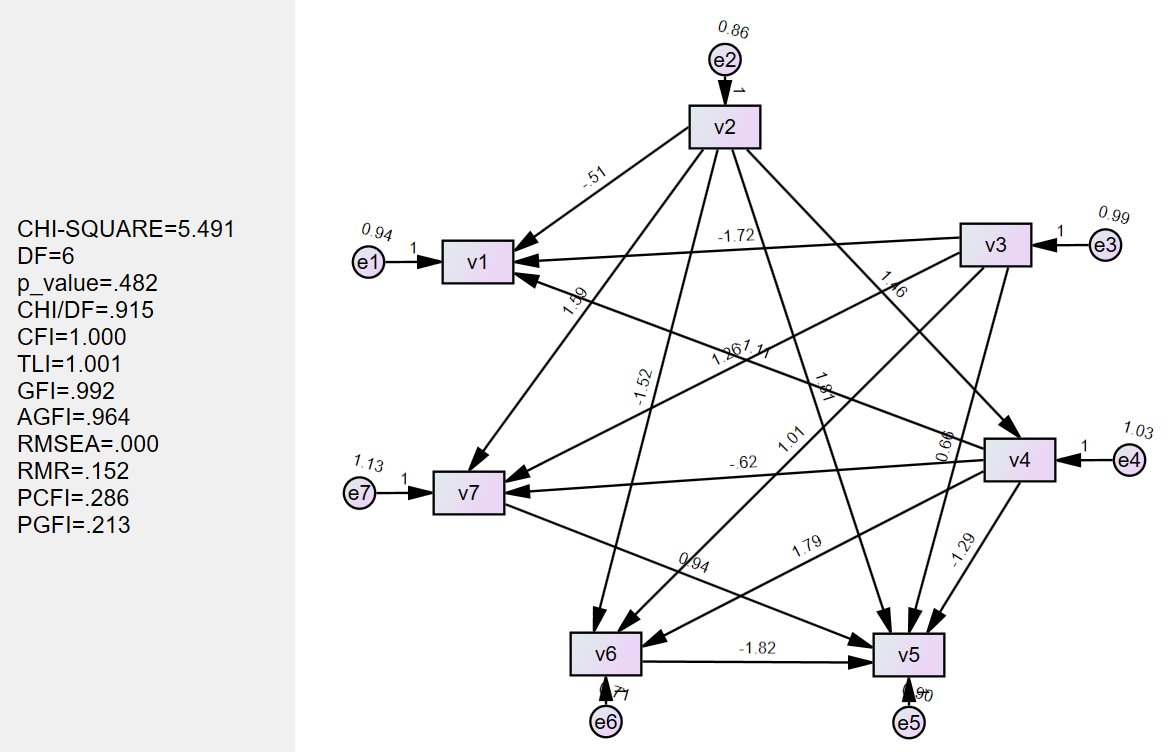
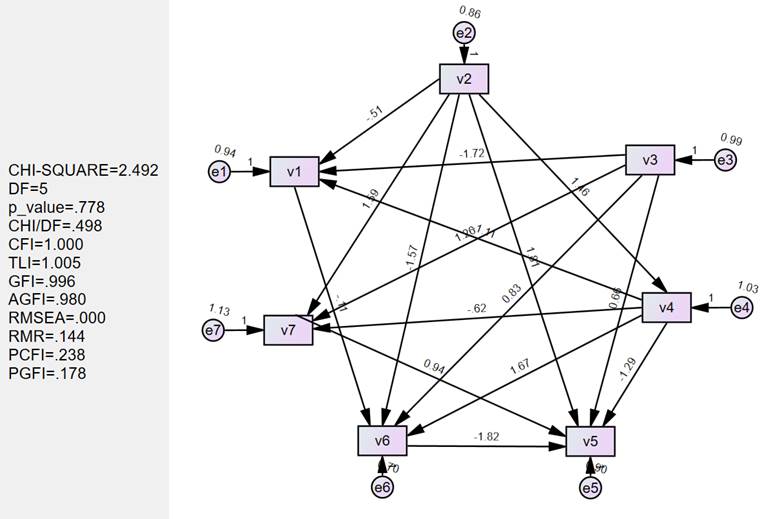
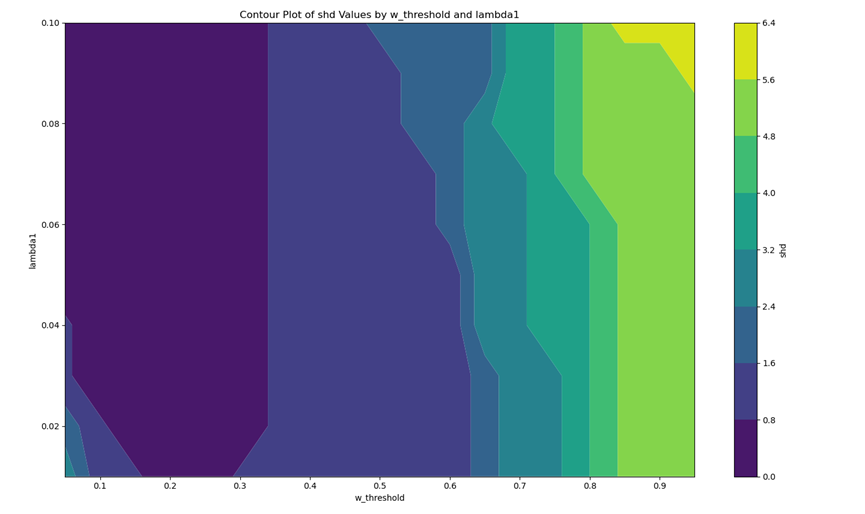
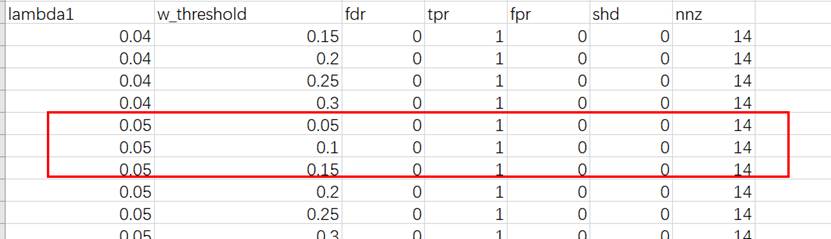
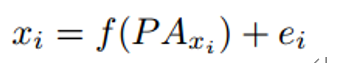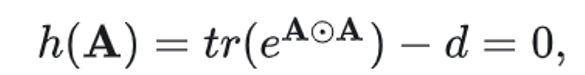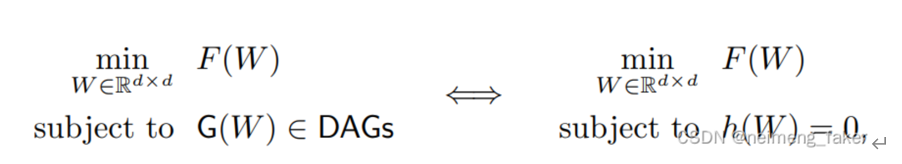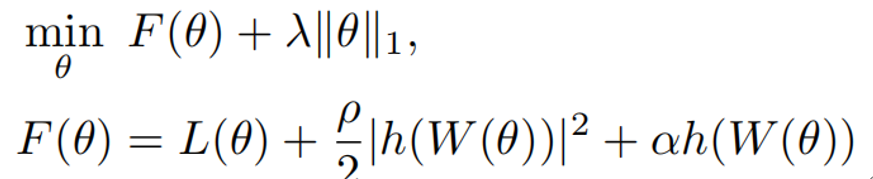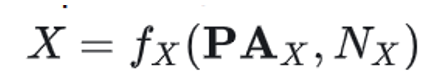PC (Hoyer等人(2008))使用加性噪声模型进行因果发现,并提供了线性非高斯因果发现框架的推广,以处理变量具有加性噪声的非线性函数依赖。它提到非线性因果关系通常有助于打破观察变量之间的对称性,并有助于确定因果方向。PC假设观测变量的数据生成过程如下面的公式所示,其中变量xi是其父变量的函数,而噪声项ei是独立的加性噪声。
三、**NOTEARS**
NOTEARS (Zheng et al .(2018))是第一个将组合图搜索问题重建为连续优化问题的,并且许多方法改造了该方法的主要贡献即无环性惩罚。强制无环性的函数/惩罚 h 为:
将传统的组合优化问题(左)转化为连续程序(右)
使用增广拉格朗日的标准机制,转换为无约束问题
四、**GraN-DAG**
基于梯度的神经DAG学习(GraN-DAG)是一种基于分数的结构学习方法,它使用神经网络(nn)来处理非线性因果关系(Lachapelle et al .(2019))。它使用随机梯度方法来训练神经网络,以提高可扩展性并允许隐式正则化。它基于NOTEARS为神经网络制定了一种新的非周期性表征(Zheng et al .(2018))。为了确保非线性模型中的非周期性,它使用了一个类似于NOTEARS的参数,并首先在神经网络路径级别应用它,然后在图路径级别应用它。对于正则化,GraN-DAG使用一个称为初步邻居选择(PNS)的过程来为每个变量选择一组潜在的父变量。它使用最后的修剪步骤来去除假边。该算法主要适用于非线性高斯加性噪声模型。
五、结构因果模型:
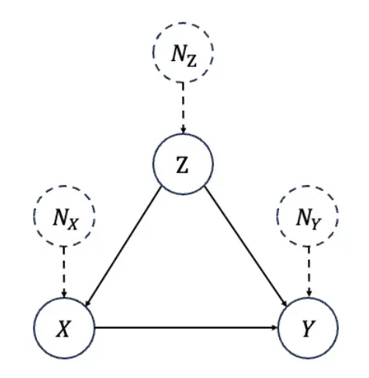
结构因果模型由 Pearl 提出,其将所有考虑的变量组织成一个有向无环图,也称作因果图 (causal graph),记作 G = (V,E) ,每个节点代表一个变量,一条由X 指向Y 的边代表X对Y有直接的因果作用。
# 线性 defrun_expt(save_data_path, num_graph, num_data_per_graph, n, d, s0, graph_type, sem_type, w_ranges, noise_scale, expt_name): # os.mkdir(expt_name) # os.chmod(expt_name, 0o777) # perf = defaultdict(list) noise_scale =np.array(noise_scale) for ii in tqdm(range(num_graph)): # B_true-生成因果图的0-1邻接矩阵 B_true = utils.simulate_dag(d, s0, graph_type) W_true = utils.simulate_parameter(B_true, w_ranges=w_ranges) B_true_fn = os.path.join(save_data_path, expt_name, f'graph{ii:05}_W_true.csv') np.savetxt(B_true_fn, B_true, delimiter=',') for jj inrange(num_data_per_graph): # X = utils.simulate_linear_sem(W_true, n, sem_type, noise_scale=noise_scale) X = utils.simulate_linear_sem(W_true, n, sem_type, noise_scale=noise_scale) X_fn = os.path.join(save_data_path, expt_name, f'graph{ii:05}_data{jj:05}_X.csv') np.savetxt(X_fn, X, delimiter=',')
# 非线性 defrun_expt_(save_data_path, num_graph, num_data_per_graph, n, d, s0, graph_type, sem_type, noise_scale, expt_name): noise_scale = np.array(noise_scale) for ii in tqdm(range(num_graph)): B_true = utils.simulate_dag(d, s0, graph_type) B_true_fn = os.path.join(save_data_path, expt_name, f'graph{ii:05}_W_true.csv') np.savetxt(B_true_fn, B_true, delimiter=',') for jj inrange(num_data_per_graph): X = utils.simulate_nonlinear_sem(B_true, n, sem_type, noise_scale=noise_scale) X_fn = os.path.join(save_data_path, expt_name, f'graph{ii:05}_data{jj:05}_X.csv') np.savetxt(X_fn, X, delimiter=',')
if __name__ == '__main__': main()
网格搜索代码:
from notears import linear, nonlinear, utils import numpy as np
withopen(r'D:\Desktop\TBFILE\学习\群体智能\群体智能第二次实验\notears-master\data\equal_var\graph00001_W_true.csv') as f: line = f.readline() data_array = [] while line: num = list(map(float, line.split(','))) data_array.append(num) line = f.readline() B_true = np.array(data_array)
withopen(r'D:\Desktop\TBFILE\学习\群体智能\群体智能第二次实验\notears-master\data\equal_var\graph00001_data00001_X.csv') as f: line = f.readline() data_array = [] while line: num = list(map(float, line.split(','))) data_array.append(num) line = f.readline() X = np.array(data_array)
import torch import torch.nn as nn import numpy as np import csv from notears.locally_connected import LocallyConnected from notears.lbfgsb_scipy import LBFGSBScipy from notears.trace_expm import trace_expm import notears.utils as ut from notears import linear, nonlinear, utils
# Define NotearsMLP and NotearsSobolev classes here (as provided)
defsquared_loss(output, target): n = target.shape[0] loss = 0.5 / n * torch.sum((output - target) ** 2) return loss
# Load observational data from CSV file X = np.genfromtxt( r'D:\Desktop\TBFILE\学习\群体智能\群体智能第二次实验\exp_nonlinear_3\graph00001_data00000_X.csv', delimiter=',', skip_header=1) # Load ground truth DAG from CSV file B_true = np.genfromtxt( r'D:\Desktop\TBFILE\学习\群体智能\群体智能第二次实验\exp_nonlinear_3\graph00001_W_true.csv', delimiter=',')
result = [] for lambda1 in L1: for lambda2 in L2: for w_threshold in WT: model = nonlinear.NotearsMLP(dims=[d, 10, 1], bias=True) W_est = notears_nonlinear(model, X, lambda1=lambda1, lambda2=lambda2, w_threshold=w_threshold)
# Ensure W_est is a DAG ifnot ut.is_dag(W_est): continue# Skip this combination if it's not a DAG
# Save results for each combination ret = [lambda1, lambda2, w_threshold] ret += list(ut.count_accuracy(B_true, W_est != 0).values()) result.append(ret)
# Save results to CSV files headers = ["lambda1", "lambda2", "w_threshold"] + list(ut.count_accuracy(B_true, W_est != 0).keys()) data = [headers] + result
withopen( r'D:\Desktop\TBFILE\学习\群体智能\群体智能第二次实验\exp_nonlinear_3\grid_search_results1.csv', 'w', newline='') as file: writer = csv.writer(file) for row in data: writer.writerow(row)
if __name__ == '__main__': main() print('done')
优化结果:
lambda1
lambda2
w_threshold
fdr
tpr
fpr
shd
nnz
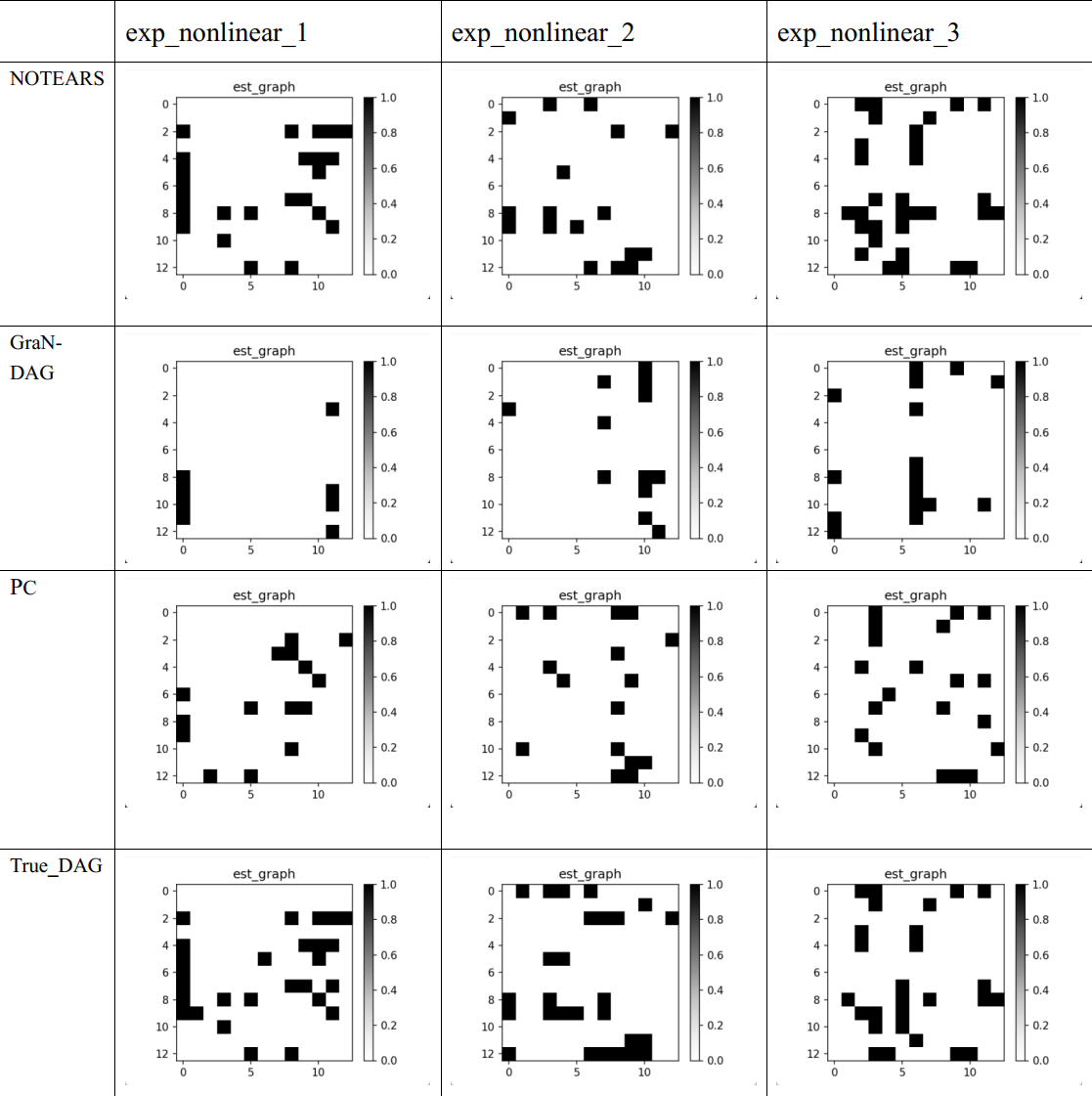
exp_nonlinear_1
0.02
0.01
0.35
0.04
0.888889
0.019608
4
25
exp_nonlinear_2
0.01
0.02
0.4
0.058824
0.592593
0.019608
11
17
exp_nonlinear_3
0.01
0.02
0.25
0.2
0.888889
0.117647
9
30
0.6.2.2. GraN-DAG
网格搜索超参数优化:
from castle.common import GraphDAG from castle.metrics import MetricsDAG from castle.algorithms import GraNDAG import numpy as np import pandas as pd import itertools
# Set random seed for reproducibility np.random.seed(42)
# Load observational data from CSV file X = np.genfromtxt( r'D:\Desktop\TBFILE\学习\群体智能\群体智能第二次实验\exp_nonlinear_1\graph00001_data00000_X.csv', delimiter=',', skip_header=1)
# Load ground truth DAG from CSV file B_true = np.genfromtxt( r'D:\Desktop\TBFILE\学习\群体智能\群体智能第二次实验\exp_nonlinear_1\graph00001_W_true.csv', delimiter=',')
# Normalize data normalize = True if normalize: X_mean = np.mean(X, axis=0, keepdims=True) X_std = np.std(X, axis=0, keepdims=True) X = (X - X_mean) / X_std
# Check for NaN values in the data if np.isnan(X).any(): raise ValueError("Input data contains NaN values. Please check the data preprocessing steps.")
# Evaluate the learned DAG mm = MetricsDAG(gnd.causal_matrix, B_true)
# Store results result = params.copy() result.update(mm.metrics) results.append(result)
# Print current result print(f"Evaluated params: {params}") print(f"Metrics: {mm.metrics}\n")
except ValueError as e: print(f"Error with params: {params}") print(e) continue
# Save results to CSV results_df = pd.DataFrame(results) results_df.to_csv(r'D:\Desktop\TBFILE\学习\群体智能\群体智能第二次实验\exp_nonlinear_1\pc_results.csv', index=False)
print("Grid search completed. Results saved to CSV.")
优化结果
hidden_num
hidden_dim
batch_size
fdr
tpr
fpr
shd
nnz
exp_nonlinear_1
2
10
128
0.5556
0.1481
0.098
28
9
exp_nonlinear_2
4
10
64
0.6667
0.1481
0.1569
28
12
exp_nonlinear_3
3
20
64
0.8
0.0741
0.1569
30
10
0.6.2.3. PC
贝叶斯搜索超参数优化:
import pandas as pd import numpy as np from castle.algorithms import PC from castle.metrics import MetricsDAG from bayes_opt import BayesianOptimization import logging
# Set up logging logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__)
# 读取CSV数据文件 data_path = r'D:\Desktop\TBFILE\学习\群体智能\群体智能第二次实验\exp_nonlinear_3\graph00001_data00000_X.csv' data = pd.read_csv(data_path)